TIP
记录来源: https://www.pdai.tech/md/interview/x-interview.html#_8-2-mysql
# 事务基本特性
- A 原子性 atomicity 在一个事务中操作要么全部成功要么全部失败
- C 一致性 consistency 数据库总是从一个一致性状态变为另一个一致性状态 事务没有提交修改不会保存到数据库
- I 隔离性 isolation 一个事务在最终提交前 对其他事务是不可见的
- D
持久性 durability 事务一旦提交 所做的修改会永久保存到数据库汇总
# 数据库并发一致性问题
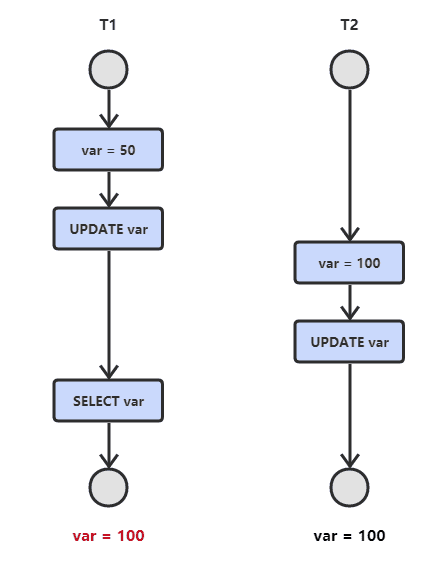
- 丢失修改
T1 T2 同事修改 T1先修改->T2修改 T2覆盖了T1的修改
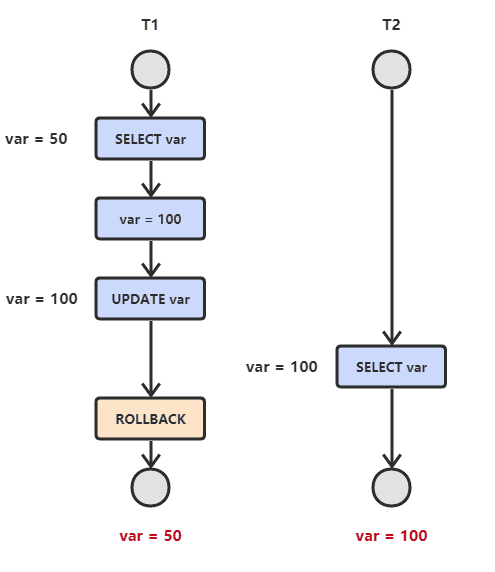
- 读脏数据
T1修改一条数据->T2读取数据->T1撤销修改 此时T2读取的数据是脏数据
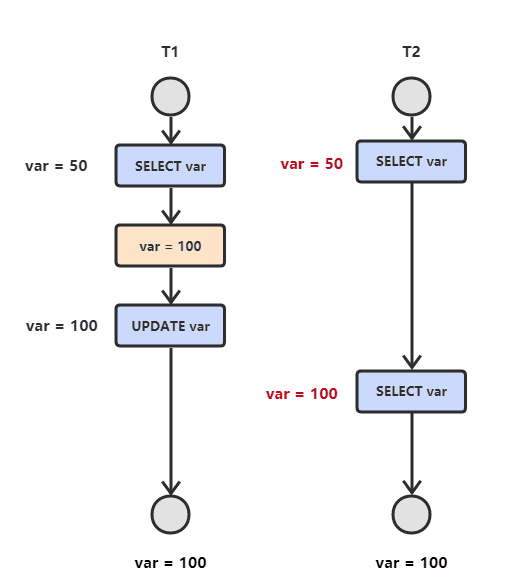
- 不可重复读
T2读取数据->T1修改数据->T2读取数据 此时T2读取结果和第一次不同
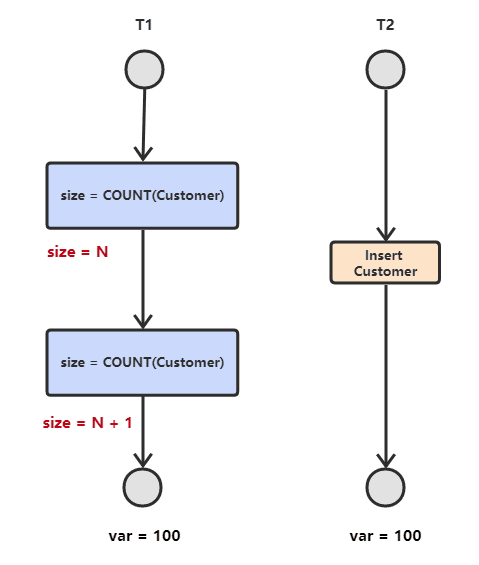
- 幻影读
T1读取范围数据->T2在这个范围插入新数据->T1再次读取这个范围数据 此时读取的结果和第一次读取结果不同
# 事务隔离级别
- 未提交读取 READ UNCOMMITTED 事务中的修改 及时没有提交,其他事务也是可见的
- 提交读取 READ COMMITTED 一个事务只能读取已提交事务所做的修改 一个事务在修改提交前对其他事务是不可见的
- 可重复读取 REPEATABLE READ 保证一个事务中多次读取同样的数据结果是一样的
- 可串行化 SERIALIZABLE 强制事务串行执行
| 隔离级别 | 脏读 | 不可重复读取 | 幻影读 |
|---|---|---|---|
| 未提交读 | √ | √ | √ |
| 提交读 | × | √ | √ |
| 可重复读 | × | × | √ |
| 可串行化 | × | × | × |
# Mysql保证ACID
- A 原子性通过 undo log保证 undo log记录需要回滚的日志信息 事务回滚已经执行的sql
- C 一致性 由代码层面保证
- I 隔离性 MVCC保证
- D 持久性 内存+redo log保证 mysql同时在 buffer pool 和redo log记录操作 事务提交的时候 通过redo log刷盘 宕机的时候从redo log恢复
# Buffer Pool、redo log buffer 、undo log 、redo log、bin log概念及其关系
- Buffer Pool mysql的组件 数据库增删查改操作全部在buffer pool中执行
- undo log 记录数据操作前的样子
- redo log 记录数据操作后的样子 InnoDB特有的
- bin log 记录整个操作记录 主要是主从复制中会使用
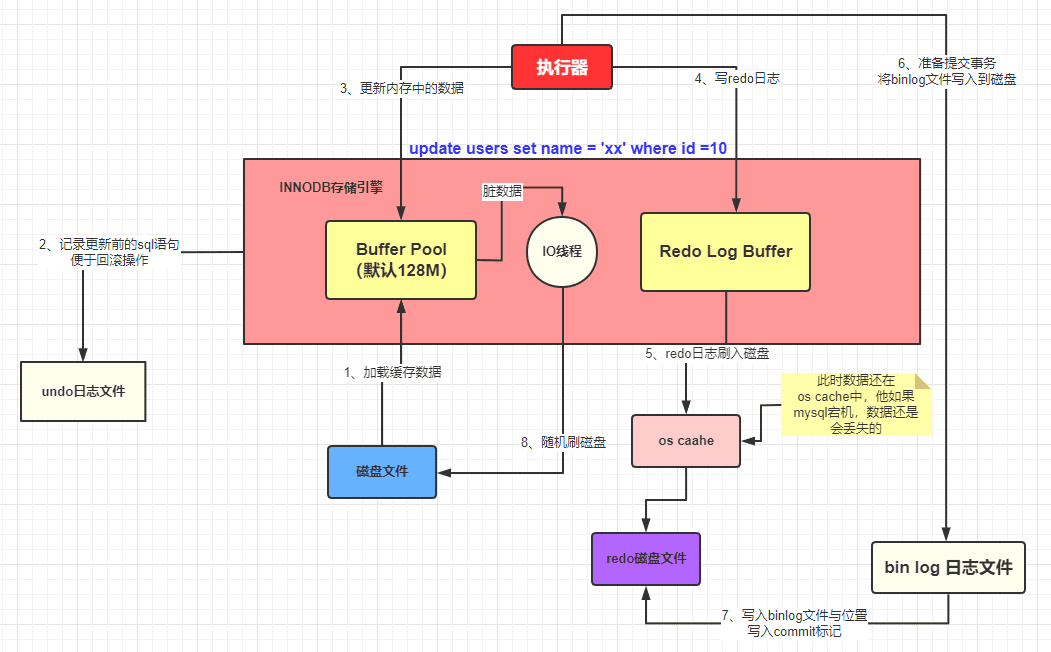
# 更新数据到事务提交的流程
- 执行器查询出具从buffer pool或者数据库中查询 命中了 放进buffer pool中
- 数据被加载到buffer pool中会写入undo log日志
- 在buffer pool中更新 更新后悔写入 redo log buffer
- 提交事务
- 将redo log buffer写入到redo log中
- 将本次操作记录到bin log中
- 将bin log文件名字和更新内容在bin log的位置 记录到 redo log中 同事redo log添加commit标记
# 引擎区别
- MyISAM
5.1版本之前默认引擎支持全文检索 压缩 空间函数 不支持事务和夯机所 不支持外键 索引和数据分开存储 适合大量查询 少量插入场景 - InnoDB
基于B+Tree索引构建支持事务 外键 通过MVCC支持高并发 索引和数据存储在一起
# 索引类型和区别
索引在存储引擎实现 不同引擎实现的索引方式不同
# B+Tree
大多数mysql存储引擎的默认索引类型
# 哈希索引
- 哈希索引能过以O(1)时间进行查找 失去有序性
- innoDB存储引擎有个特殊的 "自适应哈希索引" 当某个索引值被使用非常频繁 会在 B+Tree索引上再创建一个哈希索引 这样让B+Tree索引具有哈希索引的优势 例如快速查找
# 全文索引
- MyISAM 存储引擎支持全文索引 使用 MATCH AGAINST
- 全文索引一般使用倒排索引实现 记录关键词到其所在文档的映射
- InnoDB存储引擎在 mysql5.6.4也开始支持 全文索引
# 空间数据索引
- MyISAM存储引擎支持空间数据索引(R-Tree) 用户地理数据存储 空间数据索引会从所有纬度来索引数据 有效使用任意纬度进行组合查询
# B+Tree 和为什么B+Tree成为sql数据库的索引实现
# B+Tree
https://zhuanlan.zhihu.com/p/27700617
- B+树构建规则
*
B+树的非叶子节点不保存具体的数据,而只保存关键字的索引,而所有的数据最终都会保存到叶子节点。因为所有数据必须要到叶子节点才能获取到,所以每次数据查询的次数都一样,这样一来B+树的查询速度也就会比较稳定,而B树的查找过程中,不同的关键字查找的次数很有可能都是不同的(有的数据可能在根节点,有的数据可能在最下层的叶节点),所以在数据库的应用层面,B+树就显得更合适。
- B+树叶子节点的关键字从小到大有序排列,左边结尾数据都会保存右边节点开始数据的指针。因为叶子节点都是有序排列的,所以B+树对于数据的排序有着更好的支持。
- 非叶子节点的子节点数=关键字数(来源百度百科)(根据各种资料
这里有两种算法的实现方式,另一种为非叶节点的关键字数=子节点数-1(来源维基百科),虽然他们数据排列结构不一样,但其原理还是一样的Mysql
的B+树是用第一种方式实现);

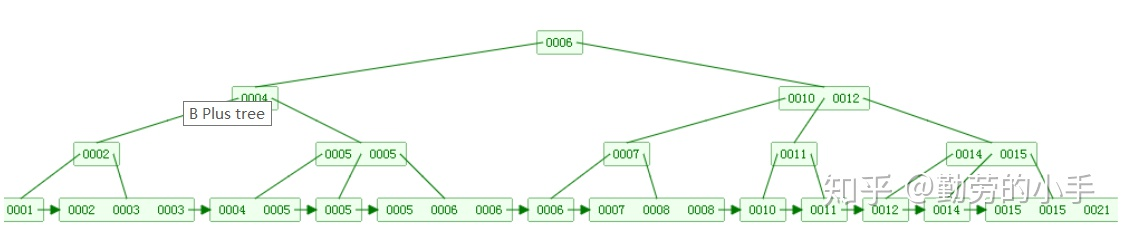
- B+树和B树的对比
- B+树查询速度更稳定:B+所有关键字数据地址都存在叶子节点上,所以每次查找的次数都相同所以查询速度要比B树更稳定。
- B+树天然具备排序功能:B+树所有的叶子节点数据构成了一个有序链表,在查询大小区间的数据时候更方便,数据紧密性很高,缓存的命中率也会比B树高。
- B+树全节点遍历更快:B+树遍历整棵树只需要遍历所有的叶子节点即可,而不需要像B树一样需要对每一层进行遍历,这有利于数据库做全表扫描。 B树相对于B+树的优点是,如果经常访问的数据离根节点很近,而B树的非叶子节点本身存有关键字和数据,所以在查询这种数据检索的时候会要比B+树快。
# 为什么是B+Tree
- 为了减少磁盘读取次数 tree的高度不能太高 所以B+Tree适合
- 以页为单位读取使得一次IO就能完全载入一个节点 且相邻节点能过被预载入 所以数据放在叶子节点 本质上是page页
- 为了支持范围查询和关联关系 页中数据需要有序 并且页的尾部节点指向下个页的头部
# B+Tree的聚簇索引和非聚簇索引
聚簇索引也叫主索引 clustered index 叶子节点保存一行数据
非鞠簇索引 叫辅助索引或者二级索引 secondary index non-clustered index 叶子节点保存是聚簇索引的关键字的值
这样设计原因 在数据发生迁移的时候 只维护聚簇索引即可 例如MyISAM 聚簇索引和非聚簇索引叶子节点都存放数据 发生了数据迁移需要对所有索引进行处理
# 覆盖索引和回表
覆盖索引指在一次查询中 如果一个索引包含或者覆盖所有需要查询字段的值 就称为覆盖索引 不需要回表查询
确定是否是覆盖索引 使用 explain 来看看sql执行计划是的 Extra的结果是否是 "Using index" 即可
# MVCC和mysql实现的MVCC原理
MVCC 全称 Multi Version Concurrency Control 多版本并发控制
在mysql的InnoDB中在已提交读(READ COMMITTED) 和可重复读取(REPEATABLE READ) 隔离级别下事务对于select
操作访问版本链中的记录过程
别的事务可以修改这条记录 select在版本链中拿记录 实现 读-写 写-读并发执行 提升系统性能
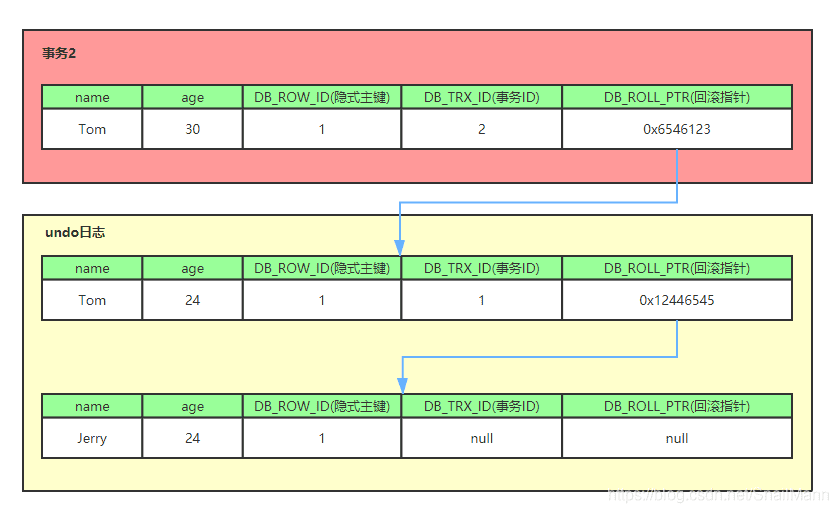
# InnoDB实现MVCC
隐式字段 提供DB_ROW_ID(数据库默认为记录生成的唯一隐式主键) DB_RTX_ID(操作当前记录的事务id) DB_ROLL_PTR(回滚指针 指向undo的上一个版本) DELETE FLAG(删除标记)

undo log
undo log 是记录每次操作之前的旧记录 undo log是记录版本的链表 链首是最新的旧记录 链尾是最早的旧记录
Read View
已提交读和可重复读区别在于生成 ReadView策略不同
ReadView 有个列表存储当前系统中活跃的读写事务(已开始未提交的事务) 通过这个列表判断记录的某个版本是否对当前事务可见
a) 如果你要访问的记录版本的事务id为50,比当前列表最小的id80小,那说明这个事务在之前就提交了,所以对当前活动的事务来说是可访问的。
b) 如果你要访问的记录版本的事务id为90,发现此事务在列表id最大值和最小值之间,那就再判断一下是否在列表内,如果在那就说明此事务还未提交,所以版本不能被访问。如果不在那说明事务已经提交,所以版本可以被访问。
c) 如果你要访问的记录版本的事务id为110,那比事务列表最大id100都大,那说明这个版本是在ReadView生成之后才发生的,所以不能被访问。这些记录都是去undo
log 链里面找的,先找最近记录,如果最近这一条记录事务id不符合条件,不可见的话,再去找上一个版本再比较当前事务的id和这个版本事务id看能不能访问,以此类推直到返回可见的版本或者结束。已提交读隔离级别事务在每次查询都会生成一个独立的ReadView 可重复读隔离级别会在第一次读的时候生成ReadView之后的读都是复用之前的ReadView
# mysql的所类型
- 共享锁(S锁)和排他锁(X锁)
- 读锁是共享 通过 lock in share mode 只能读不能写
- 写锁是排他的 阻塞其它的读锁和写锁 从颗粒度区分 分为表级别锁 和行级锁
- 表锁和行锁
- 表锁会锁定整张表并且阻塞其他用户对表的所有读写操作 如alter 修改表结构会锁表
- 行级锁分为乐观锁(for update实现 )和乐观锁(版本号实现)
# 从两个维度结合看
- 共享锁(行锁) Shared Locks
- 读锁(S锁),多个事务可以对同一数据共享访问不能修改
- 加锁: select * from table where id = ? lock in share mode
- 释放锁: commit rollback
- 读锁(S锁),多个事务可以对同一数据共享访问不能修改
- 排它锁(行锁) Exclusive Locks
- 写锁(X锁),互斥锁 独占锁 事务获取一个数据的x锁 其他事务不能在获取该数据的 读锁 写锁 只有获取了拍它锁的事务可以对数据进行读取和修改
- 加锁: DELETE UPDATE INSERT
- 加锁: select * from table where ... for update
- 释放锁: commit rollback
- 写锁(X锁),互斥锁 独占锁 事务获取一个数据的x锁 其他事务不能在获取该数据的 读锁 写锁 只有获取了拍它锁的事务可以对数据进行读取和修改
- 意向共享锁(IS)
- 一个数据行家共享锁之前 先要获得表的 IS锁 意向共享锁之间可以互相兼容 意向排他锁IX 一个数据加排他锁之前必须获取IX锁 一下拍他锁也是可以互相兼容 意向锁 IS IX是InnoDB引擎自动处理 当事务操作锁表的时候只需要判断意向锁是否存在 存在可以快速返回该表不能启用表锁
- 意向共享锁(IS)表锁: Intention Shared Locks 表示事务准备给数据加入共享锁
- 意向排他锁(IX)表锁: Intention Exclusive Locks 表示事务准备给数据加入拍他所
# 分表分库
- 垂直分库
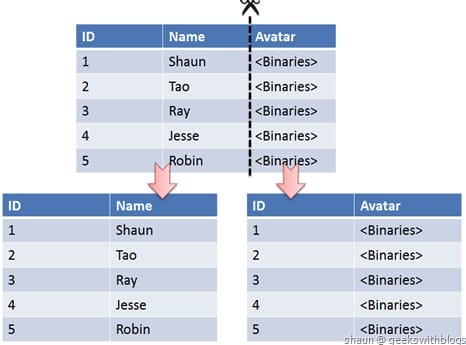
访问不同的数据库实例 例如微服务一个模块一个实例 - 垂直分表
按照字段分表 例如建立 user 和user_extra表
- 水平分表
按照数据行分表 按照id hash分散存储 或者按照时间等等
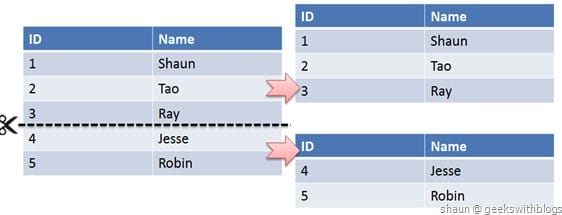
# 主键保持唯一性
- 为不同表ID设置步长 基本不用这种方式
- 使用雪花算法、uuid、自实现取号中心方式实现分布式id
# 常用实现方式
- mycat
proxy方式实现 - sharding jdbc
java项目可以直接嵌入服务中 直接在jdbc中重写sql语句 也有配套的其他方式 提供多种分表方式 提供各种广播表 数据脱敏等等插件
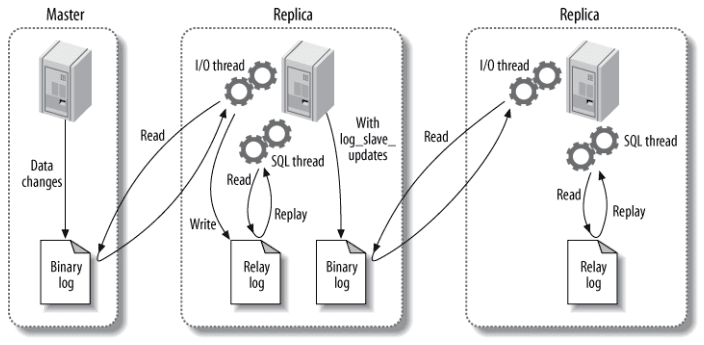
# 主从复制
- bin log线程:负责将服务器上数据更改写入二进制日志
- IO线程: 负责将主服务器上的bin log 读取并写入到从服务器的中继日志
- sql线程: 读取中继日志重放执行sql
# 全同步复制
主库写入bin log后强制同步日志到从库 所有从库执行完毕之后返回客户端
# 半同步复制
从库写入日志后返回ack给主库 主库收到至少一个从库ack就认为写入完成
# 读写分离
写入和高实时性由主服务器处理 从服务器只处理读操作
- 提高性能原因:
- 主从服务器负责各自的读写 缓解锁的竞争
- 从服务器可以使用 MyISAM 提升查询性能和节约系统开销
- 增加冗余 提高可用性
常用实现: mycat 、sharding jdbc 都可以实现 或者自己代码中按照业务去实现